Введение в MLOps
Работа содержит ошибки. Работа находится в состоянии поиска и исправления ошибок.
Отчет
Отчет в формате docx. Обязательное содержимое отчета:
- Фамилия и инициалы студента, номер группы, номер варианта;
- План и задачи лабораторной работы;
- Краткое описание хода выполнения работы;
- Скриншоты результатов заданий и ответы на вопросы задания.
Подготовка рабочего окружения
ZenML — это открытый фреймворк, который позволяет создавать пайплайны для сотрудничества между специалистами по данным, инженерами машинного обучения и платформенными инженерами для создания новых моделей ИИ.
В рамках этой лабораторной работы будет использована модель МО по предсказанию.
1. Выбор датасета
Нам необходимо автоматизировать прогнозирующую ML модель. Для этого подоберем хороший набор данных (например, на kaggle.com). Можно воспользоваться датасетом из ранее пройденных курсов.
Удобнее всего будет использовать VS Code. Настройте виртуальное окружение и установите базовые зависимости:
catboost==1.2
joblib==1.1.0
lightgbm==3.3.2
optuna==2.10.0
streamlit==1.8.1
xgboost==1.5.2
markupsafe==1.1.1
zenml==0.35.1
2. Установка ZenML
Начиная с ZenML 0.20.0, ZenML поставляется с встроенной панелью инструментов на основе React. Эта панель инструментов позволяет наблюдать за вашими стеками, компонентами стека и графами конвейеров (DAG) в интерфейсе панели инструментов. Для доступа к этому вам необходимо запустить локальный сервер и панель инструментов ZenML, но сначала вы должны установить необходимые зависимости для сервера ZenML:
pip install zenml["server"]
Чтобы поднять сервер в первый раз, его сначала нужно инициализировать:
zenml init
Теперь можно поднимать сервер:
zenml up
Для ознакомления, можно выбрать любой логин и войти без пароля (но только для ознакомления!)
3. Модель машинного обучения
Для начала, нам необходимо выделить данные, очистить их, обучить, выполнить и только потом мы сможем запустить конвейер.
Стандартный конвейер обучения состоит из следующих шагов:
ingest_data: Загрузка данных и создание DataFrame.clean_data: Очистка данных и удаление ненужных столбцов.train_model: Обучение модели и сохранение с использованием MLflow.evaluation: Этот шаг будет оценивать модель и сохранять метрики - используя автоматическую фиксацию MLflow - в хранилище артефактов.
Использование MLflow для автоматической фиксации параметров и метрик позволяет отслеживать и анализировать процесс обучения модели.
Создадим папку /steps с соответствующим шагами.
3.1. ingest_data.py
import logging
import pandas as pd
from zenml import step
class IngestData:
'''
Извлечем данные по пути data_path.
'''
def __init__(self, data_path: str):
'''
Аргументы:
data_path: путь к набору данных
'''
self.data_path = data_path
def get_data(self):
'''
Извлечение данных
'''
logging.info(f"Ingesting data from {self.data_path}")
return pd.read_csv(self.data_path)
@step
def ingest_df(data_path: str) -> pd.DataFrame:
'''
Извлечение данных
Аргументы:
data_path: путь к набору данных
Returns:
pd.DataFrame: извлеченные данные
'''
try:
ingest_data = IngestData(data_path)
df = ingest_data.get_data()
return df
except Exception as e:
logging.error(f"Error while ingesting data: {e}")
raise e
3.2. clean_data.py
import logging
import pandas as pd
from zenml import step
@step
def clean_df(df: pd.DataFrame) -> pd.DataFrame:
pass
3.3. model_train.py
import logging
import pandas as pd
from zenml import step
@step
def train_model(df: pd.DataFrame) -> None:
'''
Обучение на основе полученных данных.
Аргументы:
df: получаемые данные
'''
pass
3.4. evaluation.py
import logging
from zenml import step
@step
def evaluate_model(df: pd.DataFrame
) -> None:
'''
Оценить модель на основе полученных данных.
Аргументы:
```
df: получаемые данные
'''
pass
4. Первый конвейер
Теперь мы создадим папку и файл /pipelines/training_pipeline.py для разворачивания первого конвейера:
from zenml import pipeline
from steps.ingest_data import ingest_df
from steps.clean_data import clean_df
from steps.model_train import train_model
from steps.evaluation import evaluate_model
@pipeline(enable_cache=True)
def train_pipeline(data_path: str):
df = ingest_df(data_path)
clean_df(df)
train_model(df)
evaluate_model(df)
5. Главный (ну почти) файл
В общем каталоге создаем главный файл run_pipeline.py
from pipelines.training_pipeline import train_pipeline
from zenml.client import Client
if __name__ == "__main__":
#Запуск конвейера
print(Client().active_stack.experiment_tracker.get_tracking_uri())
train_pipeline(data_path)
6. Пробный запуск
Предварительный запуск конвейера с помощью команды:
python run_pipeline.py
И в терминале, и на локальном сервере должно быть видно, что наш конвейер успешно запущен.
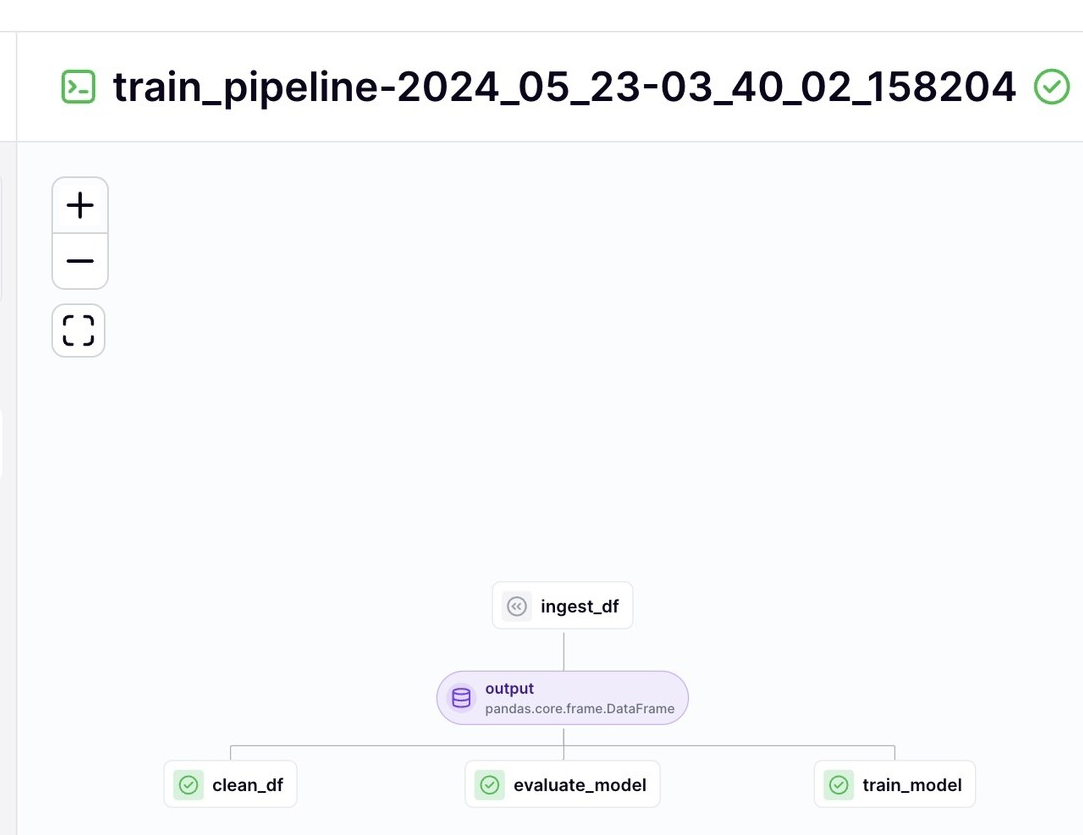
Но это был только черновик! Вы построили каркас и очертания будущего проекта, приступим к его улучшению!
7. Создадим папку /src с файлами:
7.1. /src/data_cleaning.py для тщательной очистки набора данных
Не забывайте изменять параметры относительно вашего датасета!
import logging
from abc import ABC, abstractmethod
from typing import Union
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
class DataStrategy(ABC):
'''
Абстрактный класс, определяющий алгоритм обработки данных
'''
@abstractmethod
def handle_data(self, data: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]:
pass
class DataPreProcessStrategy(DataStrategy):
'''
Алгоритм для предварительной обработки данных
'''
def handle_data(self, data: pd.DataFrame) -> pd.DataFrame:
'''
Предварительная обработка данных:
- Удаление ненужных столбцов
- Заполнение пропущенных значений медианой
- Заполнение пропущенных обзоров строкой "No review"
- Преобразование данных в числовой формат
- Удаление столбцов с категориальными данными
'''
try:
# Удаление ненужных столбцов
data = data.drop(
[
"order_approved_at",
"order_delivered_carrier_date",
"order_delivered_customer_date",
"order_estimated_delivery_date",
"order_purchase_timestamp",
],
axis=1,)
# Заполнение пропущенных зн�ачений медианой
data["product_weight_g"].fillna(data["product_weight_g"].median(), inplace=True)
data["product_length_cm"].fillna(data["product_length_cm"].median(), inplace=True)
data["product_height_cm"].fillna(data["product_height_cm"].median(), inplace=True)
data["product_width_cm"].fillna(data["product_width_cm"].median(), inplace=True)
# Заполнение пропущенных обзоров строкой "No review"
data["review_comment_message"].fillna("No review", inplace=True)
# Преобразование данных в числовой формат
data = data.select_dtypes(include=[np.number])
# Удале�ние столбцов с категориальными данными
cols_to_drop = ["customer_zip_code_prefix", "order_item_id"]
data = data.drop(cols_to_drop, axis=1)
return data
except Exception as e:
logging.error("Error in preprocessing data: {}".format(e))
raise e
class DataDevideStrategy(DataStrategy):
'''
Алгоритм разделения на тестовую и обучающую выборки
'''
def handle_data(self, data: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]:
'''
Разделение на тестовую и обучающую выборки:
- Выделение признаков (X) и целевой переменной (y)
- Разделение данных на обучающую и тестовую выборки с использованием train_test_split
'''
try:
# Выделение признаков (X) и целевой переменной (y)
X = data.drop(["review_score"], axis=1)
y = data["review_score"]
# Разделение данных на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test
except Exception as e:
logging.error("error in dividing data: {}".format(e))
raise e
class DataCleaning:
'''
Класс для очистки данных, который обрабатывает и делит их на обучающие и тестовые
'''
def __init__(self, data: pd.DataFrame, strategy: DataStrategy):
self.data = data
self.strategy = strategy
def handle_data(self) -> Union[pd.DataFrame, pd.Series]:
'''
Обработка данных
'''
try:
return self.strategy.handle_data(self.data)
except Exception as e:
logging.error("Error in handling data{}".format(e))
raise e
7.2. Обновим clean_data.py из пункта 3.2, добавив выборки
import logging
import pandas as pd
from zenml import step
from typing import Tuple
from src.data_cleaning import DataCleaning, DataDevideStrategy, DataPreProcessStrategy
from typing_extensions import Annotated
@step
def clean_df(df: pd.DataFrame) -> Tuple[
Annotated[pd.DataFrame, "X_train"], # Обучающая выборка
Annotated[pd.DataFrame, "X_test"], # Тестовая выборка
Annotated[pd.Series, "y_train"], # Целевая переменная для обучающей выборки
Annotated[pd.Series, "y_test"], # Целевая переменная для тестовой выборки
]:
'''
Чистка данных и разделение на тестовую и обучающие выборки
Аргументы:
df: Raw data
Returns:
X_train: Training data
X_test: Testing data
y_train: Training data
y_test: Testing data
'''
try:
# Инициализация стратегии предварительной обработки данных
process_strategy = DataPreProcessStrategy()
# Создание экземпляра класса DataCleaning с исходными данными и стратегией предварительной обработки
data_cleaning = DataCleaning(df, process_strategy)
# Обработка данных (предварительная обработка)
processed_data = data_cleaning.handle_data()
# Инициализация стратегии деления данных на обучающую и тестовую выборки
divide_strategy = DataDevideStrategy()
# Соз�дание экземпляра класса DataCleaning с обработанными данными и стратегией деления
data_cleaning = DataCleaning(processed_data, divide_strategy)
# Разделение обработанных данных на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = data_cleaning.handle_data()
# Логирование успешного завершения очистки данных
logging.info("Data cleaning completed")
# Возврат полученных выборок
return X_train, X_test, y_train, y_test
except Exception as e:
# Логирование ошибки в процессе очистки данных
logging.error("Error in cleaning data: {}".format(e))
raise e # Перебрасывание исключения вверх по стеку
7.3. Теперь создадим /src/model_dev, выбор модели
Вспомните что такое линейная регрессия. Предложите другие варианты моделей, которые можно было бы использовать.
import logging
from abc import ABC, abstractmethod
from sklearn.linear_model import LinearRegression
class Model(ABC):
'''
Абстрактный класс для всех моделей
'''
@abstractmethod
def train(self, X_train, y_train):
'''
Обучаем модель
Аргументы:
X_train: Training data
y_train: Training labels
Returns:
None
'''
pass
class LinearRegressionModel(Model):
'''
Линейная регрессионная модель
'''
def train(self, X_train, y_train, **kwargs):
'''
Обучим модель
Аргументы:
X_train: Training data
y_train: Training labels
Returns:
None
'''
try:
reg = LinearRegression(**kwargs)
reg.fit(X_train,y_train)
logging.info("Model training completed")
return reg
except Exception as e:
logging.error("Error in training model: {}".format(e))
raise e
# Место для вашей второй модели
7.4. Обновление кода
7.4.1. Теперь можно обновить model_train.py из п. 3.3
import logging
import pandas as pd
from sklearn.base import RegressorMixin
from zenml import step
from src.model_dev import LinearRegressionModel
@step(experiment_tracker=experiment_tracker.name)
def train_model(
X_train: pd.DataFrame,
X_test: pd.DataFrame,
y_train: pd.DataFrame,
y_test: pd.DataFrame,
config: ModelNameConfig,
) -> RegressorMixin:
try:
model = None
7.4.2. Мы еще не закончили обновлять файл, сначала создадим конфигурационный файл /steps/config.py
Он нужен, чтобы:
- Организовать и структурировать параметры конфигурации модели в одном месте.
- Упростить процесс изменения конфигураций при необходимости.
- Обеспечить стандартизацию в коде, делая его более понятным и гибким.
from zenml.steps import BaseParameters
class ModelNameConfig(BaseParameters):
"""
Настройки модели.
Данный класс наследует от BaseParameters и предназначен для
хранения конфигурационных параметров модели, таких как имя модели
и флаг, указывающий, нужно ли выполнять тонкую настройку.
"""
# Название модели, по умолчанию устанавливается 'lightgbm'
model_name: str = "lightgbm"
# Флаг, указывающий, требуется ли тонкая настройка модели.
# По умолчанию флаг установлен в False.
fine_tuning: bool = False
7.4.3. Продолжим дополнять model_train.py
import logging
import pandas as pd
from sklearn.base import RegressorMixin
from zenml import step
from src.model_dev import LinearRegressionModel
from .config import ModelNameConfig
from zenml.client import Client
@step(experiment_tracker=experiment_tracker.name)
def train_model(
X_train: pd.DataFrame,
X_test: pd.DataFrame,
y_train: pd.DataFrame,
y_test: pd.DataFrame,
config: ModelNameConfig,
) -> RegressorMixin:
'''
Обучение на основе полученных данных.
Аргументы:
X_train: pd.DataFrame,
X_test: pd.DataFrame,
y_train: pd.DataFrame,
y_test: pd.DataFrame,
'''
try:
model = None
if config.model_name == "LinearRegression":
model = LinearRegressionModel()
trained_model = model.train(X_train, y_train)
return trained_model
# При необходимости или желании, здесь можно написать условия, если вы используете больше одной модели, но не забудьте прописать новы�й класс с файле ```model_dev.py```
else:
raise ValueError("Model {} not supported".format(config.model_name))
except Exception as e:
logging.error("Error in training model: {}".format(e))
raise e
7.5. Создадим следующий файл /src/evaluation.py
! Не путайте его с evaluations.py в папке /steps !
import logging
from abc import ABC, abstractmethod
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
class Evaluation(ABC):
'''
Абстрактный класс, определяющий стратегию оценки моделей.
Этот класс служит основой (абстрактным классом) для всех классов, которые будут
реализовывать различные методы оценки, такие как MSE, R2 и RMSE.
'''
@abstractmethod
def calculate_scores(self, y_true: np.ndarray, y_pred: np.ndarray):
'''
Вычисляем баллы для модели.
Аргументы:
y_true: ndarray, истинные значения (целевые переменные).
y_pred: ndarray, предсказанные значения от модели.
Returns:
None
'''
pass # Абстрактный метод, который должен быть реализован в подклассах
class MSE(Evaluation):
'''
Алгоритм оценки, который использует среднюю квадратичную ошибку (Mean Squared Error).
'''
def calculate_scores(self, y_true: np.ndarray, y_pred: np.ndarray):
try:
logging.info("Calculating MSE")
mse = mean_squared_error(y_true, y_pred)
logging.info("MSE: {}".format(mse))
return mse
except Exception as e:
logging.error("Error in calculating MSE: {}".format(e))
raise e
class R2(Evaluation):
'''
Алгоритм оценки, который использует R2 Score.
'''
def calculate_scores(self, y_true: np.ndarray, y_pred: np.ndarray):
try:
logging.info("Calculating R2 Score")
r2 = r2_score(y_true, y_pred)
logging.info("R2 Score: {}".format(r2))
return r2
except Exception as e:
logging.error("Error in calculating R2 Score: {}".format(e))
raise e
class RMSE(Evaluation):
'''
Алгоритм оценки, который использует Root Mean Squared Error (RMSE).
'''
def calculate_scores(self, y_true: np.ndarray, y_pred: np.ndarray):
try:
logging.info("Calculating RMSE")
rmse = mean_squared_error(y_true, y_pred, squared=False)
logging.info("RMSE: {}".format(rmse))
return rmse
except Exception as e:
logging.error("Error in calculating RMSE: {}".format(e))
raise e
7.6. И наконец обновим /steps/evaluation.py из п. 3.4
import logging
from typing import Tuple
import pandas as pd
from zenml import step
from sklearn.base import RegressorMixin
from typing_extensions import Annotated
from zenml.client import Client
from src.evaluation import MSE, R2, RMSE
@step
def evaluate_model(model: RegressorMixin,
X_test: pd.DataFrame,
y_test: pd.DataFrame,
) -> Tuple[
Annotated[float, "r2_score"],
Annotated[float, "rmse"],
]:
'''
Evaluates модель на основе полученных данных.
Аргументы:
```
df: получаемые данные
'''
try:
prediction = model.predict(X_test)
mse_class = MSE()
mse = mse_class.calculate_scores(y_test, prediction)
r2_class = R2()
r2 = r2_class.calculate_scores(y_test, prediction)
rmse_class = RMSE()
rmse = rmse_class.calculate_scores(y_test, prediction)
return r2, rmse
except Exception as e:
logging.error("Error in evaluating model: {}".format(e))
raise e
8. Вернемся и обновим /pipelines/training_pipeline.py из п. 4.
Ведь теперь у нас есть выборки и метрики!
from zenml import pipeline
from steps.ingest_data import ingest_df
from steps.clean_data import clean_df
from steps.model_train import train_model
from steps.evaluation import evaluate_model
@pipeline(enable_cache=True)
def train_pipeline(data_path: str):
df = ingest_df(data_path)
X_train, X_test, y_train, y_test = clean_df(df)
model = train_model(X_train, X_test, y_train, y_test)
r2_score, rmse = evaluate_model(model, X_test, y_test)
Снова запустим конвейер командой
python run_pipeline.py
Теперь наш конвейер стал больше! Изучите метрики, посмотрите на выводы разных этапов.
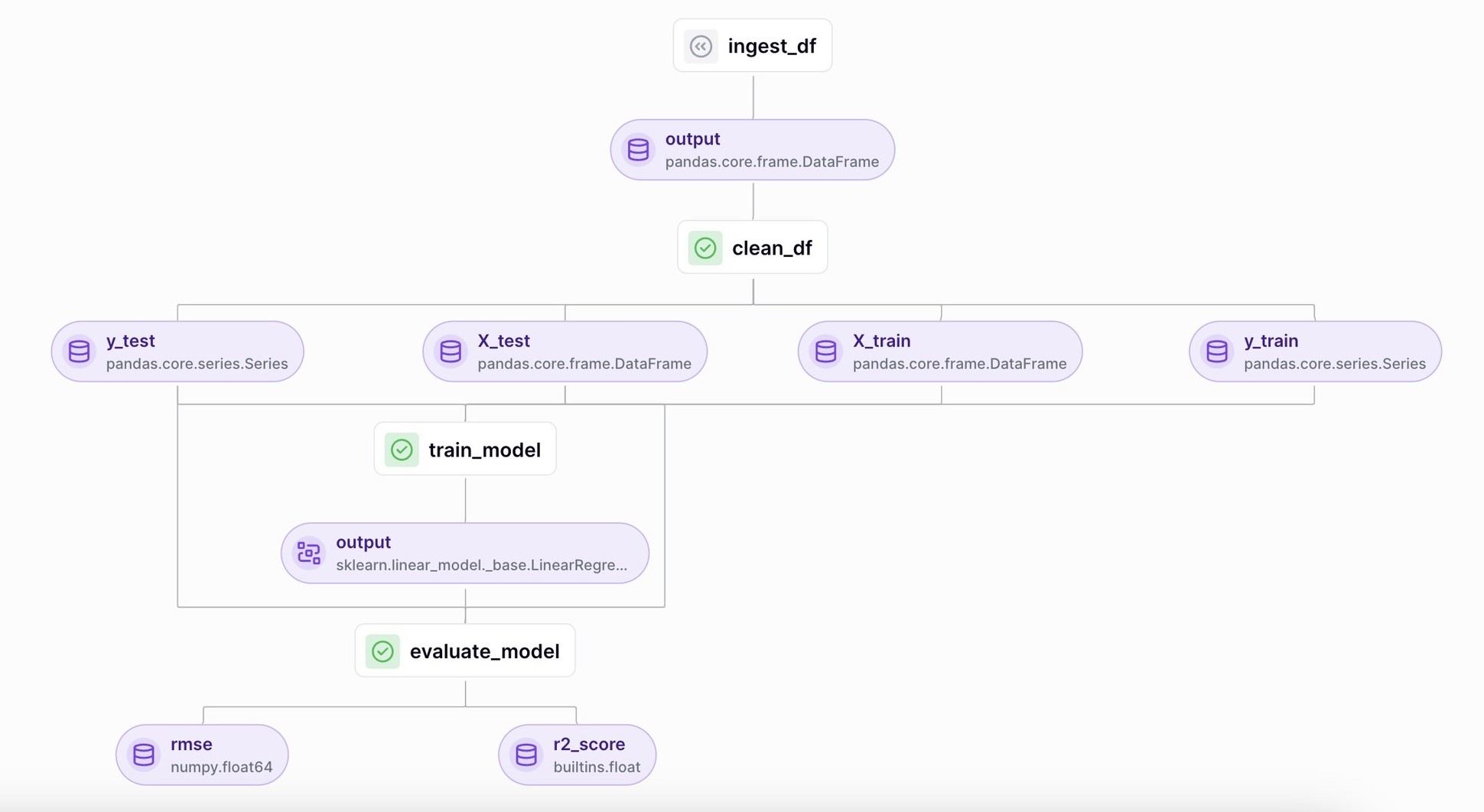
9. Трэкинг
Во время разработки крупных проектов, очень тяжело отслеживать все события, поэтому создали experiment tracker.
Трэкер позволяет отслеживать в проекте важные процессы вне зависимости от общего объема. Это важная и полезная функция, поэтому посмотрим, как она работает. Проект может быть выполнен только с использованием стека ZenML, который содержит эксперимент-трекер и модуль развертывания моделей MLflow в качестве компонентов. Обн�овим некоторые файлы.
- В
model_train.pyпосле объявлений укажем:
import mlflow
from zenml.client import Client
experiment_tracker = Client().active_stack.experiment_tracker
@step(experiment_tracker=experiment_tracker.name)
# Остальной код
try:
model = None
if config.model_name == "LinearRegression":
mlflow.sklearn.autolog()
# Остальной код
- Похожие правки нужны в
/steps/evaluation.py
import mlflow
...
experiment_tracker = Client().active_stack.experiment_tracker
...
@step(experiment_tracker=experiment_tracker.name)
...
mse = mse_class.calculate_scores(y_test, prediction)
mlflow.log_metric("mse", mse)
r2_class = R2()
r2 = r2_class.calculate_scores(y_test, prediction)
mlflow.log_metric("r2", r2)
rmse_class = RMSE()
rmse = rmse_class.calculate_scores(y_test, prediction)
mlflow.log_metric("rmse", rmse)
Конфигурирование нового стека с двумя этими компонентами выглядит следующим образом:
zenml integration install mlflow -y
zenml experiment-tracker register mlflow_tracker --flavor=mlflow
zenml model-deployer register mlflow --flavor=mlflow
zenml stack register mlflow_stack -a default -o default -d mlflow -e mlflow_tracker --set
Выведем результат:
zenml stack describe
И получим такую таблицу
| COMPONENT_TYPE | COMPONENT_NAME |
|---|---|
| ORCHESTRATOR | default |
| ARTIFACT_STORE | default |
| MODEL_DEPLOYER | mlflow |
| EXPERIMENT_TRACKER | mlflow_tracker |
Теперь запустим MLFlow, для отслеживания наших трэкеров. После запуска run_pipeline.py вы увидите в терминале путь к отслеживаемому трэкеру.
Вставьте этот путь в комнаду
mlflow ui --backend-store-uri “<file:path>”
Например:
mlflow ui --backend-store-uri "file:/Users/Iana/Library/Application Support/zenml/local_stores/0c496041-e535-44a0-8d4c-b340cde8590e/mlruns"
При успешном запуске в терминале мы получим адрес локального сервера на MLFlow, где мы можем отслеживать наш проект.

Непосредственно, интерфейс MLFlow со всеми нашими пайплайнами.
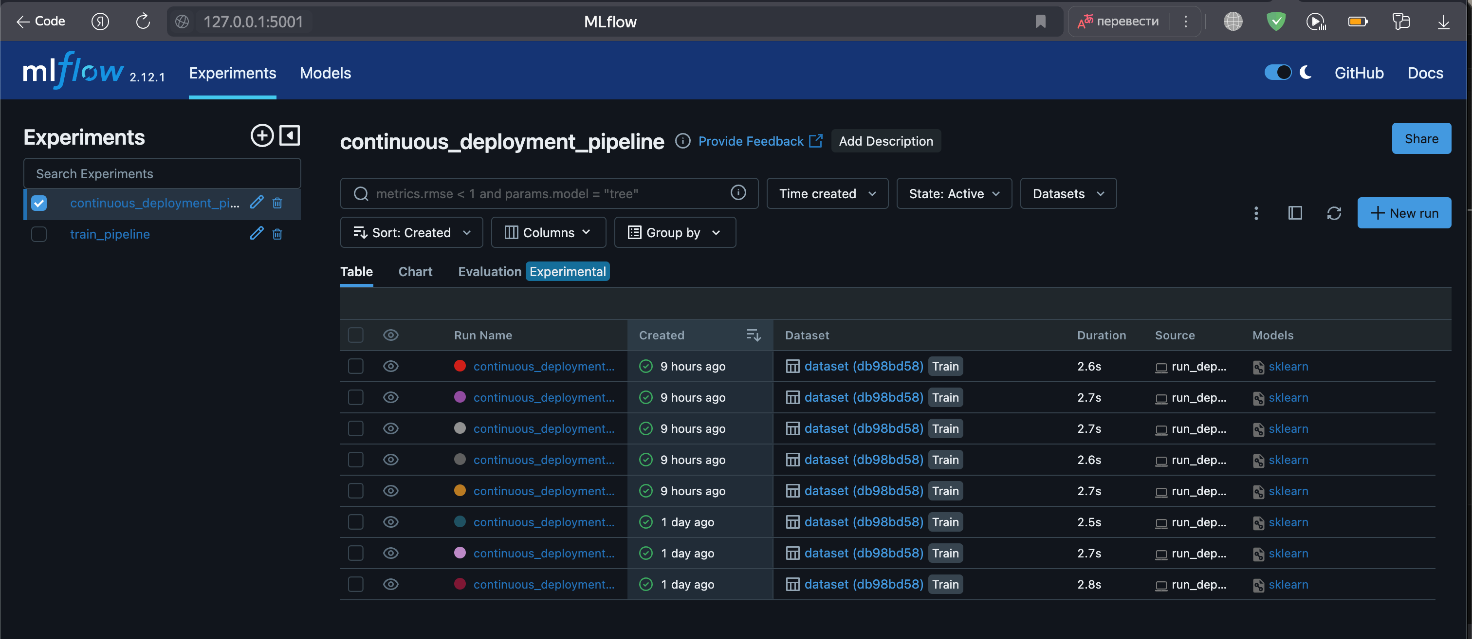
10. Автоматизация
Перейдем к финальной части нашего проекта. Развернем непрерывный конвейер и добавим предиктор для прогнозирования.
На деле у нас будет два конвейера, каждый из которых нужно описать.
Создадим в общем каталоге файл run_deployment.py
from typing import cast
import click
from pipelines.deployment_pipeline import (
deployment_pipeline,
inference_pipeline,
) # Добавим немного позже
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict"
@click.command()
@click.option(
"--config",
"-c",
type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]),
default=DEPLOY_AND_PREDICT,
help="Вы выбираете, чтобы или запустить"
"конвейер развертывания для обучения и развертывания модели (`deploy`),"
"или конвейер предсказание для развернутой модели (`predict`).
" По умолчанию будут выполнены оба действия (`deploy_and_predict`).",
)
@click.option(
"--min-accuracy",
default=0.92, # Выбирайте значение относительно результатов Ваших метрик!
help="Минимальная точность, необходимая для развертывания модели",
)
def main(config: str, min_accuracy: float):
if deploy:
deployment_pipeline(min_accuracy)
if predict:
inference_pipeline()
if __name__ == "__main__":
main()
Каркас написан, перейдем к деталям.
11.1. Пайплайн развертывания (deployment pipeline)
Создадим файл по пути /pipelines/deployment_pipeline.py.
import numpy as np
import pandas as pd
from zenml import pipeline, step
from zenml.config import DockerSettings
from zenml.constants import DEFAULT_SERVICE_START_STOP_TIMEOUT
from zenml.integrations.constants import MLFLOW
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import (
MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
from zenml.steps import BaseParameters, Output
from steps.clean_data import clean_df
from steps.evaluation import evaluate_model
from steps.ingest_data import ingest_df
from steps.model_train import train_model
# Настройка Docker с необходимыми интеграциями
docker_settings = DockerSettings(required_integrations=[MLFLOW])
class DeploymentTriggerConfig(BaseParameters):
'''Конфигурация триггера развертывания'''
min_accuracy: float = 0.92 # Не забывайте вводить корректные и подходящие вашим метрикам значения!!!
@step
def deployment_trigger(
accuracy: float,
config: DeploymentTriggerConfig
):
```Реализует простой триггер развертывания модели, который проверяет точность входной модели и определяет,
достаточно ли она хороша для развертывания```
return accuracy > config.min_accuracy
# Определение конвейера непрерывного развертывания
@pipeline(enable_cache=False, settings={"docker": docker_settings})
def continuous_deployment_pipeline(
data_path: str,
min_accuracy: float = 0.92, # Не забывайте вводить корректные и подходящие вашим метрикам значения!!!
workers: int = 1,
timeout: int = DEFAULT_SERVICE_START_STOP_TIMEOUT,
):
# Загрузка данных из указанного пути
df = ingest_df(data_path=data_path)
# Очистка данных и разделение на тренировочные и тестовые наборы
X_train, X_test, y_train, y_test = clean_df(df)
# Обучение модели
model = train_model(X_train, X_test, y_train, y_test)
# Оценка модели
r2_score, rmse = evaluate_model(model, X_test, y_test)
# Принятие решения о развертывании на основе точности модели
deployment_decision = deployment_trigger(r2_score)
# Шаг развертывания модели с использованием MLflow
mlflow_model_deployer_step(
model=model,
deploy_decision=deployment_decision,
workers=workers,
timeout=timeout,
)
11.2. Теперь можно подробнее расписать непрерывное развертывание в run_deployment.py
import click
from typing import cast
import click
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline
) # Добавим немного позже
from zenml.integrations.mlflow.mlflow_utils import get_tracking_uri
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import (
MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict"
@click.command()
@click.option(
"--config",
"-c",
type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]),
default=DEPLOY_AND_PREDICT,
help="Вы выбираете, чтобы или запустить"
"конвейер развертывания для обучения и развертывания модел�и (`deploy`),"
"или конвейер предсказание для развернутой модели (`predict`).
" По умолчанию будут выполнены оба действия (`deploy_and_predict`).",
)
@click.option(
"--min-accuracy",
default=0.92, # Выбирайте значение относительно результатов Ваших метрик!
help="Минимальная точность, необходимая для развертывания модели",
)
def main(config: str, min_accuracy: float):
"""Запустите примерный конвейер MLflow."""
# Получите компонент стека развертывания модели MLflow
mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer()
deploy = config == DEPLOY or config == DEPLOY_AND_PREDICT
predict = config == PREDICT or config == DEPLOY_AND_PREDICT
if deploy:
# Инициализируйте запуск конвейера непрерывного развертывания
continuous_deployment_pipeline(
data_path="Путь до вашего набора данных", # НЕ забудьте поменять!
min_accuracy=min_accuracy,
workers=3,
timeout=60,)
if predict:
inference_pipeline()
print(
"Вы можете запустить:\n "
f"[italic green] mlflow ui --backend-store-uri '{get_tracking_uri()}"
"[/italic green]\n ...чтобы просмотреть свои запуски экспериментов в интерфейсе MLflow"
" UI.\nВы можете найти свои запуски, отслеживаемые в эксперименте "
"`mlflow_example_pipeline`. Там вы также сможете "
"сравнить два или более запусков.\n\n"
)
# Получите существующие службы с тем же именем конвейера, именем шага и именем модели
existing_services = mlflow_model_deployer_component.find_model_server(
pipeline_name="continuous_deployment_pipeline",
pipeline_step_name="mlflow_model_deployer_step",
model_name="model",
)
if existing_services:
service = cast(MLFlowDeploymentService, existing_services[0])
if service.is_running:
print(
f"Сервер предсказаний MLflow запущен локально как демонов "
f"и принимает запросы на предсказания по адресу:\n"
f" {service.prediction_url}\n"
f"Чтобы остановить службу, выполните "
f"[italic green]`zenml model-deployer models delete "
f"{str(service.uuid)}`[/italic green]."
)
elif service.is_failed:
print(
f"Сервер предсказаний MLflow находится в состоянии сбоя:\n"
f" Последнее состояние: '{service.status.state.value}'\n"
f" Последняя ошибка: '{service.status.last_error}'"
)
else:
print(
"В данный момент сервер предсказаний MLflow не работает. Конвейер "
"развертывания должен быть запущен сначала для обучения модели и ее развертывания. "
"Выполните ту же команду с аргументом `--deploy`, чтобы развернуть модель."
)
if __name__ == "__main__":
main()
Теперь мы можем запустить новый конвейер, пока без прогнозирования.
python run_deployment.py --config deploy
11.3. Добавим в /pipelines/deployment_pipeline.py конвейер для предсказаний
# Остальной код
docker_settings = DockerSettings(required_integrations=[MLFLOW])
@step(enable_cache=False)
def dynamic_importer() -> str:
data = get_data_for_test()
return data
# Остальной код
class MLFlowDeploymentLoaderStepParameters(BaseParameters):
# Параметры шага загрузки развертывания MLFlow
pipeline_name: str # Имя конвейера
step_name: str # Им�я шага
running: bool = True # Поле, определяющее, запущен ли сервис (по умолчанию True)
@step(enable_cache=False)
def prediction_service_loader(
pipeline_name: str,
pipeline_step_name: str,
running: bool = True,
model_name: str = "model",
) -> MLFlowDeploymentService:
# Получение активного компонента развертывателя модели MLFlow
mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer()
# Поиск существующих служб развертывания
existing_services = mlflow_model_deployer_component.find_model_server(
pipeline_name=pipeline_name,
pipeline_step_name=pipeline_step_name,
model_name=model_name,
running=running,
)
# Если службы не найдены, выбрасываем ошибку
if not existing_services:
raise RuntimeError(
f"Служба развертывания MLFlow не найдена для конвейера {pipeline_name}, "
f"шага {pipeline_step_name} и модели {model_name}. "
f"Конвейер для модели '{model_name}' в данный момент запущен."
)
return existing_services[0] # Возврат первой найденной службы
@step
def predictor(
service: MLFlowDeploymentService,
data: str,
) -> np.ndarray:
"""Запускает запрос предсказаний к сервису предсказания"""
service.start(timeout=10) # Запуск сервиса (должен быть без операции, если уже запущен)
data = json.loads(data) # Загрузка данных из строки JSON
data.pop("columns") # Удаление колонки "columns"
data.pop("index") # Удаление колонки "index"
# Определение колонок для DataFrame
columns_for_df = [
"payment_sequential",
"payment_installments",
"payment_value",
"price",
"freight_value",
"product_name_lenght",
"product_description_lenght",
"product_photos_qty",
"product_weight_g",
"product_length_cm",
"product_height_cm",
"product_width_cm",
] # Не забывайте менять параметры по вашему набору данных!
# Создание DataFrame из данных
df = pd.DataFrame(data["data"], columns=columns_for_df)
json_list = json.loads(json.dumps(list(df.T.to_dict().values()))) # Преобразование в формат JSON
data = np.array(json_list) # Преобразование в массив NumPy
# Получение предсказания от сервиса
prediction = service.predict(data)
return prediction # Возврат предсказания
# Остальной код
11.4. Также необходимо создать файл /pipelines/utils.py для сбора данных для тестирования
import logging
import pandas as pd
from model.data_cleaning import DataCleaning, DataPreprocessStrategy
def get_data_for_test():
try:
df = pd.read_csv("./путь до вашего csv")
df = df.sample(n=100)
preprocess_strategy = DataPreprocessStrategy()
data_cleaning = DataCleaning(df, preprocess_strategy)
df = data_cleaning.handle_data()
df.drop(["review_score"], axis=1, inplace=True)
result = df.to_json(orient="split")
return result
except Exception as e:
logging.error(e)
raise e
импортируйте в deploy_pipeline. py from .utils import get_data_for_test
11.5. Продолжим вносить изменения в deployment_pipeline.py, для вывода заключений
# После def continuous_deployment_pipeline
@pipeline(enable_cache=False, settings={"docker": docker_settings})
def inference_pipeline(pipeline_name: str, pipeline_step_name: str):
# Link all the steps artifacts together
data = dynamic_importer()
service = prediction_service_loader(
pipeline_name=pipeline_name,
pipeline_step_name=pipeline_step_name,
running=False,
)
prediction = predictor(service=service, data=data)
return prediction
12.1. Пайплайн предсказания (inference pipeline)
Обновим run_deployment.py
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline,
inference_pipeline,
)
И распишем predict
if predict:
# Инициализируйте запуск конвейера предсказания
inference_pipeline(
pipeline_name="continuous_deployment_pipeline",
pipeline_step_name="mlflow_model_deployer_step",
)
12.2. Чтобы запустить конвейер с прогнозированием, изменим соответствующий флаг в команде:
python run_deployment.py --config predict
На сервере Zenml проследите за новым конвейером и изучите предикт в графе Meta.
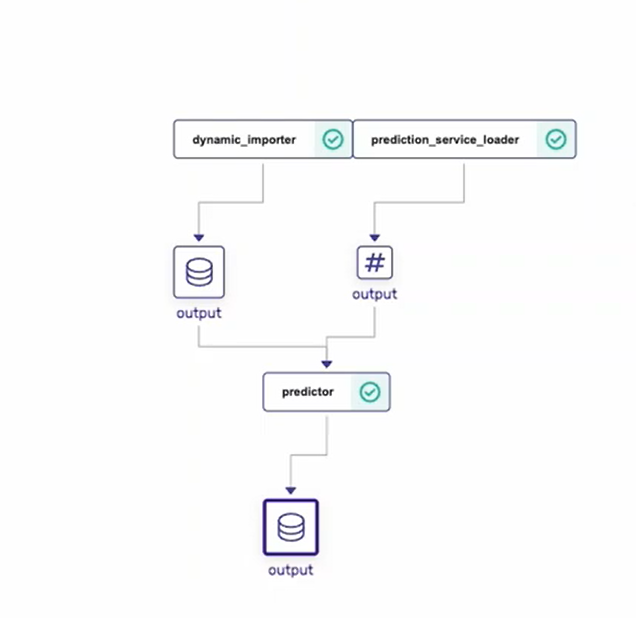
Для запуска в MLFlow воспользуйтесь командой, которую вы использовали ранее.
Если вы не прекратили предыдущий процесс, новый иногда нужно запустить на другом порте с помощью флага
--port
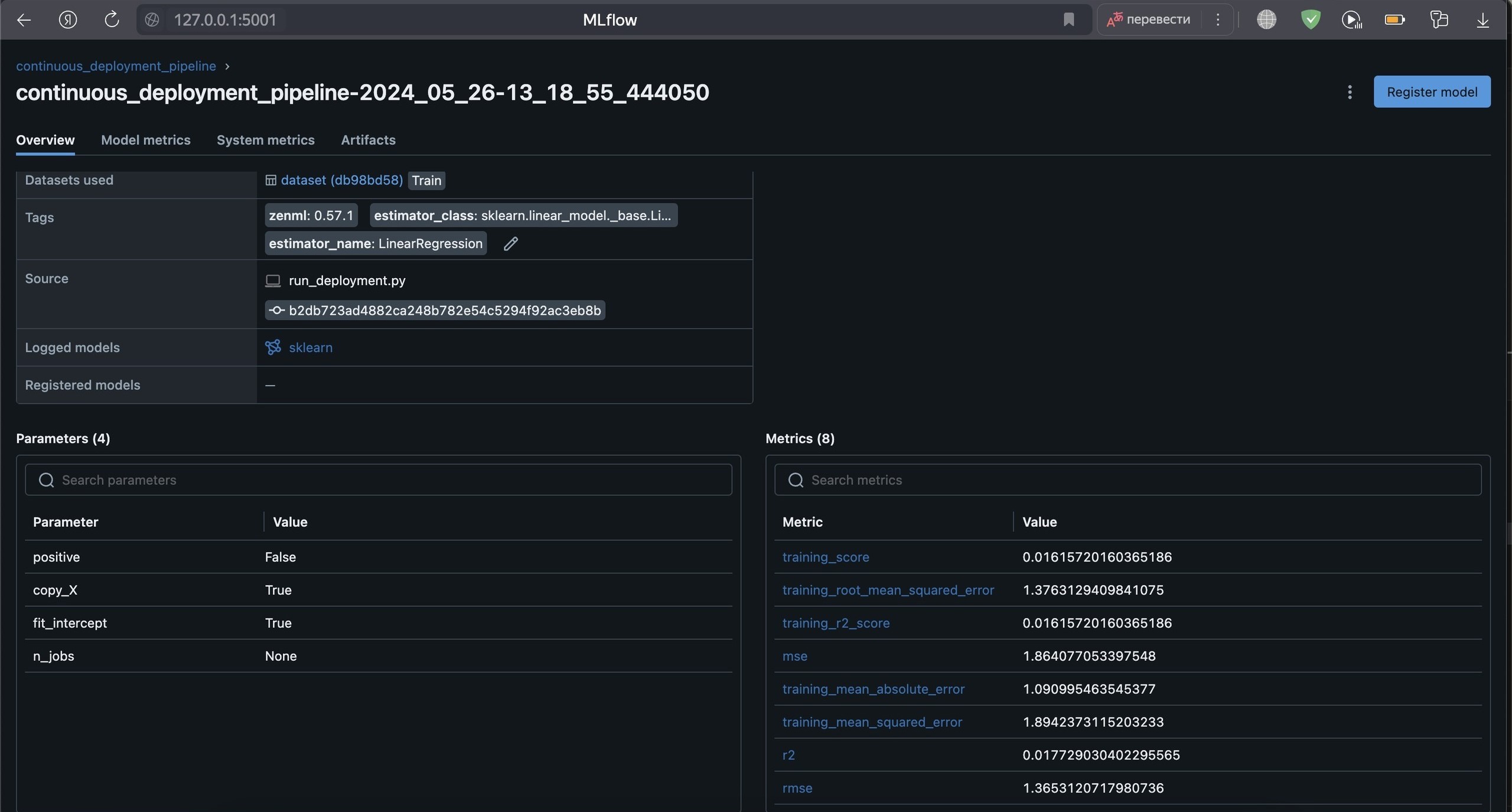
Изучите полученные в MLFlow метрики. Сделайте выводы.
13. Streamlit приложение
Для удобства использования прогнозов (предиктов) создадим простое streamlit приложение.
Не забывайте изменять описания и параметры относительно вашего датасета!
В корневом каталоге создадим файл streamlit_app.py
import json
import numpy as np
import pandas as pd
import streamlit as st
from PIL import Image
from pipelines.deployment_pipeline import prediction_service_loader
from run_deployment import main
def main():
st.title("End to End Customer Satisfaction Pipeline with ZenML")
'''
st.markdown(
"""
#### Задача:
Цель заключается в том, чтобы предсказать оценку удовлетворенности клиента для данного заказа на основе таких характеристик, как статус заказа, цена, оплата и т.д. Я буду использовать [ZenML](https://zenml.io/) для построения готовой к производству конвейера для прогнозирования оценки удовлетворенности клиента для следующего заказа или покупки. """
)
st.markdown(
"""
Сначала мы получаем данные, очищаем их, обучаем модель и оцениваем её. Если источник данных изменится или значения гиперпараметров изменятся, это вызовет развертывание, и модель будет (пере)обучена. Если модель соответствует минимальным требованиям по точности, она будет развернута.
"""
)'''
st.markdown(
"""
#### Описание характеристик
Это приложение предназначено для прогнозирования оценки удовлетворенности клиента для данного клиента. Вы можете ввести характеристики продукта, перечисленные ниже, и получить оценку удовлетворенности клиента.
| Models | Description |
| ------------- | - |
| Payment Sequential | Customer may pay an order with more than one payment method. If he does so, a sequence will be created to accommodate all payments. |
| Payment Installments | Number of installments chosen by the customer. |
| Payment Value | Total amount paid by the customer. |
| Price | Price of the product. |
| Freight Value | Freight value of the product. |
| Product Name length | Length of the product name. |
| Product Description length | Length of the product description. |
| Product photos Quantity | Number of product published photos |
| Product weight measured in grams | Weight of the product measured in grams. |
| Product length (CMs) | Length of the product measured in centimeters. |
| Product height (CMs) | Height of the product measured in centimeters. |
| Product width (CMs) | Width of the product measured in centimeters. |
"""
)
payment_sequential = st.sidebar.slider("Payment Sequential")
payment_installments = st.sidebar.slider("Payment Installments")
payment_value = st.number_input("Payment Value")
price = st.number_input("Price")
freight_value = st.number_input("freight_value")
product_name_length = st.number_input("Product name length")
product_description_length = st.number_input("Product Description length")
product_photos_qty = st.number_input("Product photos Quantity ")
product_weight_g = st.number_input("Product weight measured in grams")
product_length_cm = st.number_input("Product length (CMs)")
product_height_cm = st.number_input("Product height (CMs)")
product_width_cm = st.number_input("Product width (CMs)")
if st.button("Предсказать"):
service = prediction_service_loader(
pipeline_name="continuous_deployment_pipeline",
pipeline_step_name="mlflow_model_deployer_step",
running=False,
)
if service is None:
st.write(
"No service could be found. The pipeline will be run first to create a service."
)
run_main()
df = pd.DataFrame(
{
"payment_sequential": [payment_sequential],
"payment_installments": [payment_installments],
"payment_value": [payment_value],
"price": [price],
"freight_value": [freight_value],
"product_name_lenght": [product_name_length],
"product_description_lenght": [product_description_length],
"product_photos_qty": [product_photos_qty],
"product_weight_g": [product_weight_g],
"product_length_cm": [product_length_cm],
"product_height_cm": [product_height_cm],
"product_width_cm": [product_width_cm],
}
)
json_list = json.loads(json.dumps(list(df.T.to_dict().values())))
data = np.array(json_list)
pred = service.predict(data)
st.success(
"Оценка удовлетворенности вашего клиента (в диапазоне от 0 до 5) с учетом предоставленных деталей продукта составляет: :-{}".format(
pred
)
)
'''if st.button("Результаты"):
st.write(
"Мы провели эксперименты с двумя ансамблевыми и древовидными моделями и сравнили эффективность каждой модели. Результаты следующие:"
)
df = pd.DataFrame(
{
"Models": ["LightGBM", "Xgboost"],
"MSE": [1.804, 1.781],
"RMSE": [1.343, 1.335],
}
)
st.dataframe(df)
if __name__ == "__main__":
main()
Для запуска используйте команду:
streamlit run streamlit_app.py
14. Итоговая структура проекта
MLOps
├── data
│ └── dataset.csv
├── pipelines
| ├── deployment_pipeline.py
| ├── training_pipeline.py
│ └── utils.py
├── src
| ├── data_cleaning.py
│ ├── evaluation.py
│ └── model_dev.py
├── steps
| ├── clean_data.py
│ ├── config.py
│ ├── evaluation.py
│ ├── ingest_data.py
│ └── model_train.py
├── .gitignore
├── __init__.py
├── README.md
├── requirements.txt
├── run_deployment.py
├── run_pipeline.py
└── streamlit_app.py