Мастер-класс по наблюдаемости системы
Часть 1. Основы наблюдаемости системы
Джентльменский набор хорошего проекта
- Сервера под управлением некоторой ОС
- Сеть и сетевое оборудование
- Вспомогательное (DNS, DHCP, Backup, ...)
- Continuous integration / Continuous delivery (CI/CD)
- Load balancing (LB), fault-tolerance (FT), high availability (HA)
- Supervision, orchestration, auto-scaling, service discovery
- Logging & monitoring & tracing
- Infrastructure automation & infrastructure as code (IaC)
Что такое наблюдаемость
Наблюдаемость в контексте распределенной системы — это возможность отслеживать и анализировать данные телеметрии о состоянии каждого компонента, иметь возможность наблюдать за изменениями производительности и диагностировать причины возникновения этих изменений.
В отличие от отладки, которая является инвазивной (способной проникать) и может повлиять на работу приложения, наблюдаемость предназначена для прозрачной основной операции и имеет небольшое влияние на производительность, которое может быть использовано непрерывно.
Телеметрия - данные, собранных средствами наблюдаемости.
3 столпа наблюдаемости
- Логи (aka журналы), которые записывают отдельные операции, такие как входящий запрос, сбой в определенном компоненте или размещение заказа.
- Метрики, которые измеряют счетчики и датчики, такие как количество завершенных запросов, активные запросы и задержки запроса.
- Распределенная трассировка, которая отслеживает запросы и действия между компонентами в распределенной системе, чтобы увидеть, где время тратится и отслеживает конкретные сбои.
Преимущества наблюдения
Наблюдение за системой даёт ряд преимуществ:
- Ускорение разрешения инцидентов;
- Повышение быстродействия системы;
- Эффективное планирование ресурсопотребления;
- Повышение эффективности разработки;
- Более эффективное сотрудничество;
- Повышение надёжности системы.
Преимущества наблюдения в деталях
- Отображает текущее и предыдущее состояние системы. Например, так можно узнать, что ночью нагрузка системы достигала 70%, а потому, возможно, нужно добавить новый инстанс.
- Демонстрирует, как пользователи пользуются системой. Например, какие действия пользователя популярны, какие кнопки чаще всего нажимают пользователи.
- Подсвечивает, где и как уменьшить затраты на работу системы. Предположим, по телеметрии видно, что из четырех инстансов реально работает только один — и тот на 20%. В таком случае можно отказаться от двух лишних (базовый минимум – два инстанса).
- Оптимизирует CI/CD-пайплайны. Например, если один из степов билда или деплой занимает много времени, то с телеметрией можно увидеть, что именно занимает так много времени и когда эти проблемы начались.
Уровни наблюдаемости

Наблюдаемость можно рассмотреть в разрезе уровней, каждый базируется на предыдущем:
- Наверху оповещения как результат выполнения аналитической функции от метрик, собираемых в процессе мониторинга на базе логов и иных показателей.
- Внизу находится аудит, позволяющий отследить изменения в системе, помогает и в выявлении причин проблем.
Аудит
Аудит с точки зрения наблюдаемости - возможность локализовать изменения, которые могли привести к проблемам. Это помогают нам сделать контроль версий и системы контроля версий.
1-ый столп наблюдения: логирование
- Автоматические – генерируются с помощью фреймворка или сервиса (CI/CD в GitLab). С помощью этих данных можно логировать, например, какой реквест пришел и получился, что было внутри реквеста. С автоматическими логами ничего не нужно делать для сбора данных, что удобно для рутинных задач.
- Мануальные – нужно запускать вручную. Не так просто, как с автоматическими, но это оправданно при логовании важных частей системы. Это обычно нагруженные или нацеленные на бизнес-задачи процессы. Скажем, в образовательной системе будет значимой проблемой потерять тесты студентов за определенный период.
Обычно логировать все данные ненужно. Оцените систему, найдите наиболее уязвимые и ценные части системы. Скорее всего, там нужно добавить логов.
Данные в логах могут включать информационные сообщения, предупреждения, ошибки и прочую инф�ормацию, обычно сохраняемую в файле журнала или базе данных:
Сопутствующие цели логирования
- Аудит: с помощью логирования можно отслеживать пользовательскую активность в системе или приложении, получая информацию о том, кто, к каким данным и когда обращался.
- Соответствие требованиям: логирование можно использовать для выполнения нормативных требований или требований совместимости, таких как HIPAA (акт о мобильности и подотчётности медицинского страхования) или PCI-DSS (стандарт безопасности данных платёжных карт), которые предписывают хранение и анализ определённых типов данных.
- Мониторинг производительности: с помощью ло�гирования можно отслеживать метрики производительности, такие как время отклика или использование ресурсов, используя их для оптимизации быстродействия системы.
Уровни логирования
debug- отладочная информация, которая чаще всего используется при тестировании системы;info- средней важности информация, чаще всего регистрирующая факт свершения некоторого события;warn- предупреждения о потенциальных ошибках конфигурации или приближении крупных проблем;error- ошибка свершилась, пора с ней разбираться.
Крайне малое совершенно неинформативных логов, либо чрезвыйная их избыточность, которая затруднит анализ логов даже с использованием специальных инструментов!
Сценарии использования логов
- Самый очевидный сценарий - у пользователя произошла ошибка или не дай бог упал какой-то сервис и нужно быстро разобраться, что же пошло не так.
- Наступление событий. Здесь важно сделать акцент на том, что такие события могут быть вызвана как действием пользователя, так и результатом асинхронных задач. Однако важно, чтобы частота отслеживаемых событий не была большой.
- Отслеживание пользовательской активности. Отличие этого случая от второго в том, что при отслеживании активности подразумевается, что частота совершаемых действий может быть достаточно большой.
- Отлаживание функциональности. Вот тут то пригодятся наиболее подробные логи. Однако подобным лучше заниматься на тестовых стендах, где интенсивность логов не такая высокая.
Примеры использования сценариев логирования
Случай 1. Ошибки:
- В случае задуманной ошибки: в
debug. Пример: ошибка 404. - В случае неожиданной ошибки: подробный лог в
error. Пример: ошибка записи в базу данных. Берем объект, с которым возникла ошибка и целиком его логируем вместе со всеми полями (исключая совсем приватные), а также логируем данные из запроса пользователя (контекст).
Случай 2. Наступление событий:
Мы пытаемся понять причину возникнувшей ошибки, нам может быть недостаточно контекста и мы захотим понять историю действий пользователя или даже обработки конкретного запроса (см. далее распределенную трассировку).
Случай 3. Отслеживание пользовательской активности:
Фиксация действий пользователя в наиболее сложных сценариях или наиболее критичных для бизнеса. То есть принципиальное отличие от случая 2 в том, что отслеживание пользовательской активности позволяет разработчику понять, что делал пользователь до наступления ошибки.
Случай 4. Отладка:
Отладочные логи, к сожалению, неизбежно раздувают размер файлов с исходным кодом, так как их приходится писать достаточно много. Плюс на это тратиться драгоценное время, однако использование отладочных логов позволяет сэкономить время при внесении изменений в код, продиктованных как рефакторингом, так и изменением хотелок бизнеса.
Отладочные логи можно включать на конкретные компоненты системы.
Как выполнять логирование
- Логирование приложений: многие языки программирования и фреймворки предоставляют встроенную поддержку логирования приложения, позволяя разработчикам логировать сообщения на разных уровнях важности (например, информационные, предупреждения, ошибки), распределяя их по разным категориям.
- Системное логирование: операционные системы и сетевые устройства зачастую предоставляют свои механизмы логирования для перехвата системных событий, таких как авторизация, ошибки и использование ресурсов.
- Логирование с помощью агентов: многие инструменты логирования и сервисы предоставляют агентов или библиотеки, которые можно установить в системы или приложения для сбора данных логов.
- Контейнерное логирование: контейнеризованные приложения, выполняющиеся на таких платформах, как Docker или Kubernetes, генерируют данные логов, специфичные для среды контейнера.
- Облачное логирование: многие облачные платформы и сервисы предоставляют механизмы логирования для перехвата событий и данных, связанных с облачными ресурсами, такими как виртуальные машины, базы данных и сервисы приложений.
2-ой столп наблюдения: метрики
- Автоматические – метрики, которые предоставляет система. Например, в Windows можно увидеть показатели нагрузки на CPU, количество реквестов и т.д. В большинстве облачных платфор�м вы сможете обнаружить метрику на станицах управления виртуальными машинами. Там можно найти количество данных, которые поступают в систему или исходят из нее.
- Мануальные – можете добавлять их сами. Например, когда нужно видеть актуальное количество подписок на сервис. Это можно реализовать через логи, но их нужно сосчитать. С метриками все смотрится наглядно и понятно для клиента.
Примеры метрик
- Метрики производительности, такие как время отклика, пропускная способность и частота ошибок.
- Метрики потребления ресурсов, такие как использование ЦПУ, памяти и дисковой системы ввода-вывода.
- Бизнес-метрики, такие как доход, вовлечённость пользователей и удовлетворённость клиентов.
Примеры бизнес-метрик
- Использование фичей — интенсивность использования фичи клиентами. Помогает определить, стоит ли вкладываться в развитие фичи в том виде, в котором она сейчас представлена.
- Время выполнения задачи клиентом — насколько быстро клиент может зарегистрироваться в системе, насколько быстро может оформить покупку, насколько быстро может подготовить отчет, в общем, — насколько быстро клиент достигает результата.
- Сколько клиентов и на каком этапе перестают пользоваться продуктом с контекстом состояния продукта (например, каким было время отклика в этот момент).
- Бизнес-метрики в разрезе различных вариантов реализации при A/B-тестировании (контрольная группа элементов сравнивается с набором тестовых групп).
Методологии сбора метрик
- Google SRE: Latency (время, необходимое вашей службе для выполнения запроса.), Traffic ( насколько велик спрос на ваши услуги), Errors (частота сбоев в работе вашего сервиса), Saturation (насыщенность — показатель того, насколько близки к полному использованию ресурсы сервис).
- Метод USE: Utilization (процент времени, когда выполнялась полезная работа), Saturation, Errors
- Метод RED: Rate ( количество запросов в секунду, которые обслуживают ваши сервисы), Errors, Duration (распределение количества времени, затрачиваемого на каждый запрос).
Как собирать метрики
- Реализация: метрики можно собирать �путём реализации кода внутри приложения или системы. Это подразумевает добавление кода для перехвата определённых метрик, таких как время отклика или частота ошибок, и отправки их в систему мониторинга.
- Метрики на основе логов: метрики также можно извлекать из данных журналов, сгенерированных приложениями или системами. Этот подход включает извлечение метрик из файлов журналов, например количеств определённых типов событий или ошибок, и их отправку в систему мониторинга.
- Системные метрики: операционные системы и компоненты инфраструктуры, такие как серверы, сети и базы данных, обычно отражают встроенные метрики, которые можно собирать и мониторить с помощью инструментов системы.
- Сторонние сервисы: многие облачные сервисы предоставляют встроенные метрики, к которым можно обращаться и мониторить через API или веб-интерфейсы.
Какой бы метод ни использовался, важно, чтобы метрики собирались с подходящей частотой и точностью, и сохранялись при этом удобным для запроса и анализа образом.
Мониторинг
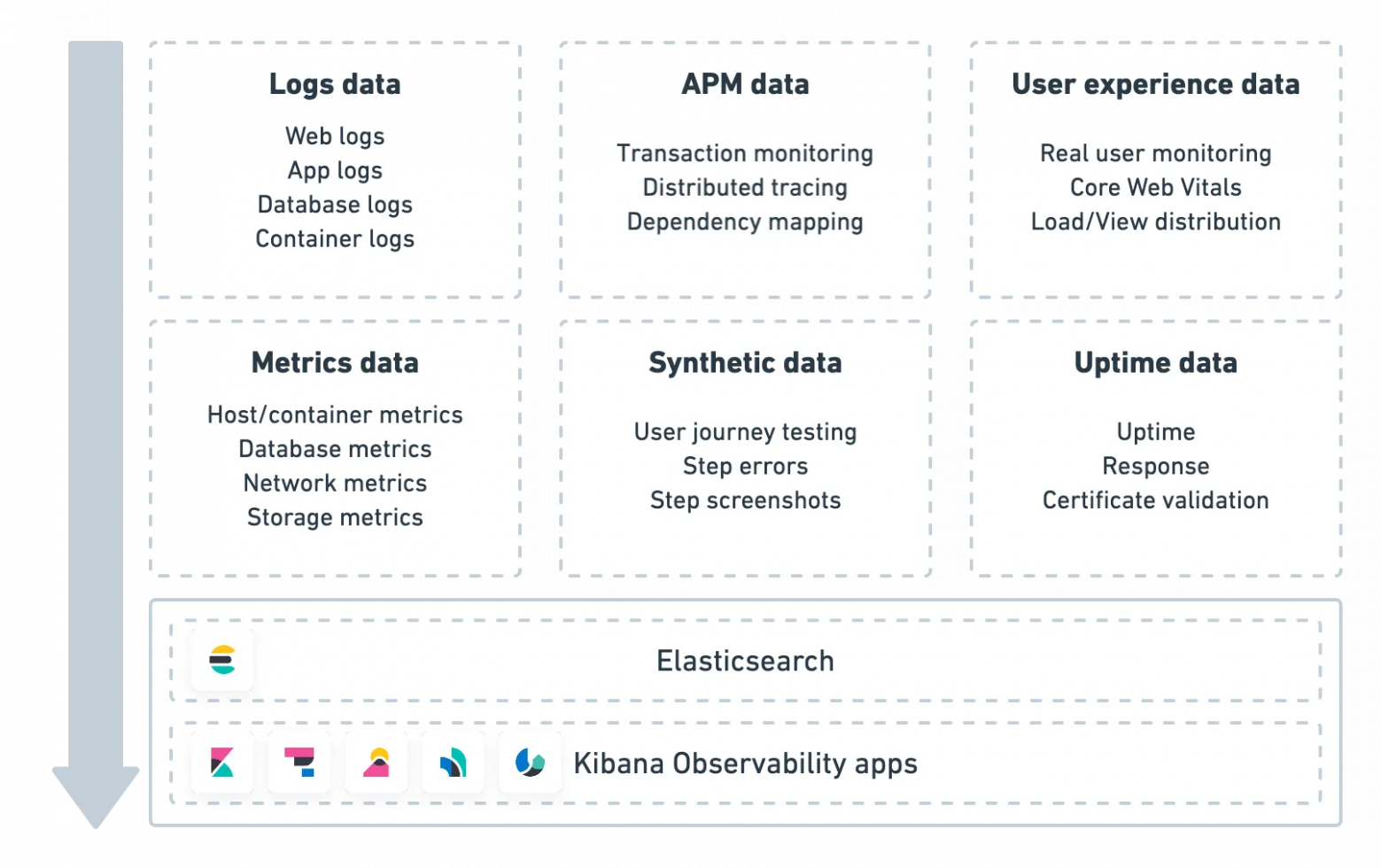
Мониторинг системы – это процесс наблюдения и сбора данных о производительности, поведении и состоянии компьютерной системы либо приложения.
Цель мониторинга – обеспечение оптимальной работы системы и приложений, а также определение и разрешение проблем по мере их возникновения.
Пример данных, собираемым в ходе системного мониторинга
- Метрики производительности: определение времени отклика, пропускной способности и частоты ошибок помогает понять, насколько хорошо работает система или приложение.
- Метрики использования ресурсов: определение использования ЦПУ, памяти и дискового ввода-вывода помогает понять, каким образом задействуются ресурсы системой или приложением.
- Данные журналов: журналы системы или приложений помогают разобраться в их поведении, а также могут использоваться для исправления проблем и выявления ошибок.
Виды мониторинга

- top, atop, iostat, ...
- Push metrics (Zabbix, Carbon, ...)
- Pull metrics (Prometheus, VM)
Как проводить мониторинг
- Сбор данных: инструменты мониторинга системы собирают данные из различных источников, таких как журналы, счётчики производительности или API. Данные можно собирать в реальном времени либо в пакетах, что зависит от требований программы мониторинга.
- Хранение данных: после сбора данные мониторинга помещаются в хранилище, такое как база данных временных рядов или агрегатор логов. Обычно данные сохраняются в структурированном формате, что позволяет их эффективно запрашивать и анализировать.
- Анализ данных: инструменты мониторинга анализируют собранные данные с целью выявления тенденций, паттернов и проблем. Этот анализ можно выполнять с помощью различных техник, таких как статистический анализ, машинное обучение или оповещения на основе порогов.
- Отчёты и визуализация: результаты анализа обычно представляются в виде отчётов, сводных таблиц или оповещений. Эти данные помогают понять производительность и поведение системы, а также выявить проблемы до того, как они станут критическими.
3-ий столп наблюдения: распределенная трассировка
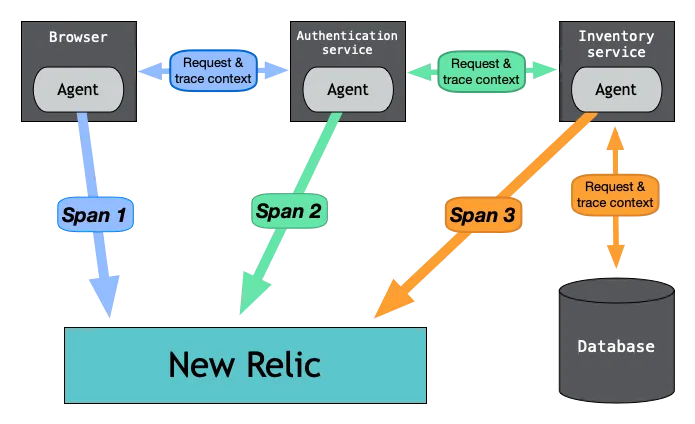
Распределенная трассировка – это техника мониторинга и отладки крупных распределённых систем. Она подразумевает реализацию кода для генерации трейсов, представляющих собой записи активности отдельных запросов по мере их прохождения через систему. Впоследствии эти трейсы агрегируются для предоставления подробной картины обработки запросов различными компонентами системы.
Как выполнять распределенную трассировку
- Работает эта техника путём генерации и распространения контекста трейса (trace context) по распределённой системе.
- Когда сервис получает запрос, он генерирует контекст трейса, включающий уникальный trace ID и span ID.
- Trace ID используется для определения самого запроса, а span ID определяет конкретную операцию или активность в рамках этого запроса.
- Когда запрос обрабатывается сервисом, контекст трейса передаётся другим сервисам, задействованным в этой обработке.
- Каждый сервис в процессе обработки генерирует новые спаны и добавляет их в контекст трейса. Так создаётся цепочка спанов, представляющая весь путь запроса через систему.
- Полный контекст трейса возвращается клиенту либо сохраняется в бэкенде трассировки в конце обработки запроса.
- Затем контекст трейса можно визуализировать и проанализировать для лучшего понимания производительности и поведения системы.
Оповещения
Оповещения – это способ автоматического уведомления причастных сторон о возникновении в системе или приложении конкретного события или состояния.
Цель оповещений в том, чтобы быстро выявлять и реагировать на проблемы на ранних стадиях.

Примеры условий отправки оповещений
- Использование ресурсов: когда система или приложение превышает заданный порог использования процессора, памяти или прочих метрик ресурсов.
- Сообщения ошибок: когда в журнале приложения или системы обнаруживаются сообщения об ошибках, указывающие на проблему.
- Метрики производительности: когда метрики производительности, такие как время отклика или объём транзакции, выходят за установленный порог.
- Инциденты безопасности: в случае обнаружения событий, связанных с безопасностью, таких как провалы авторизации или попытки неавторизованного доступа.
Средства мониторинга
- Nagios (1999)
- Zabbix (2001)
- Pandora FMS (2004)
- Prometheus (2012, Go) – система приложений для мониторинга на основе временных рядов
- Carbon + Graphite (2017, python)
- VictoriaMetrics (2018, Go) – полностью совместимая замена с сохранением всех интерфейсов Prometheus ...
Nagios
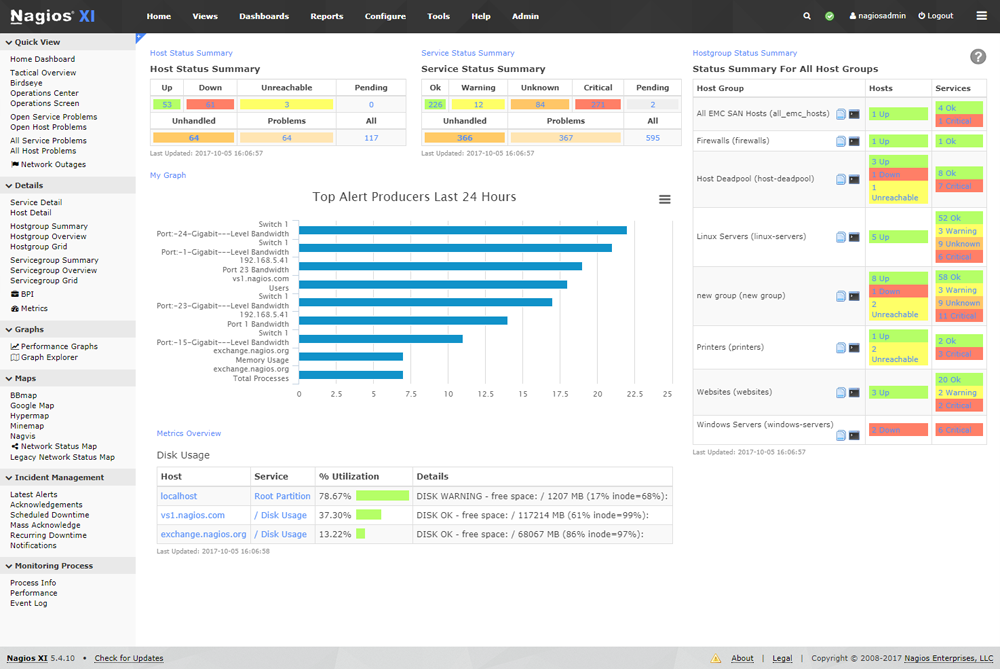
- Одна из первых популярных систем мониторинга.
- Ныне по всем параметрам уступает Zabbix и Pandora FMS.
- Nagios с нами уже почти четверть века. Это хорошо, но это также влечет за собой некоторые ограничения.
Zabbix
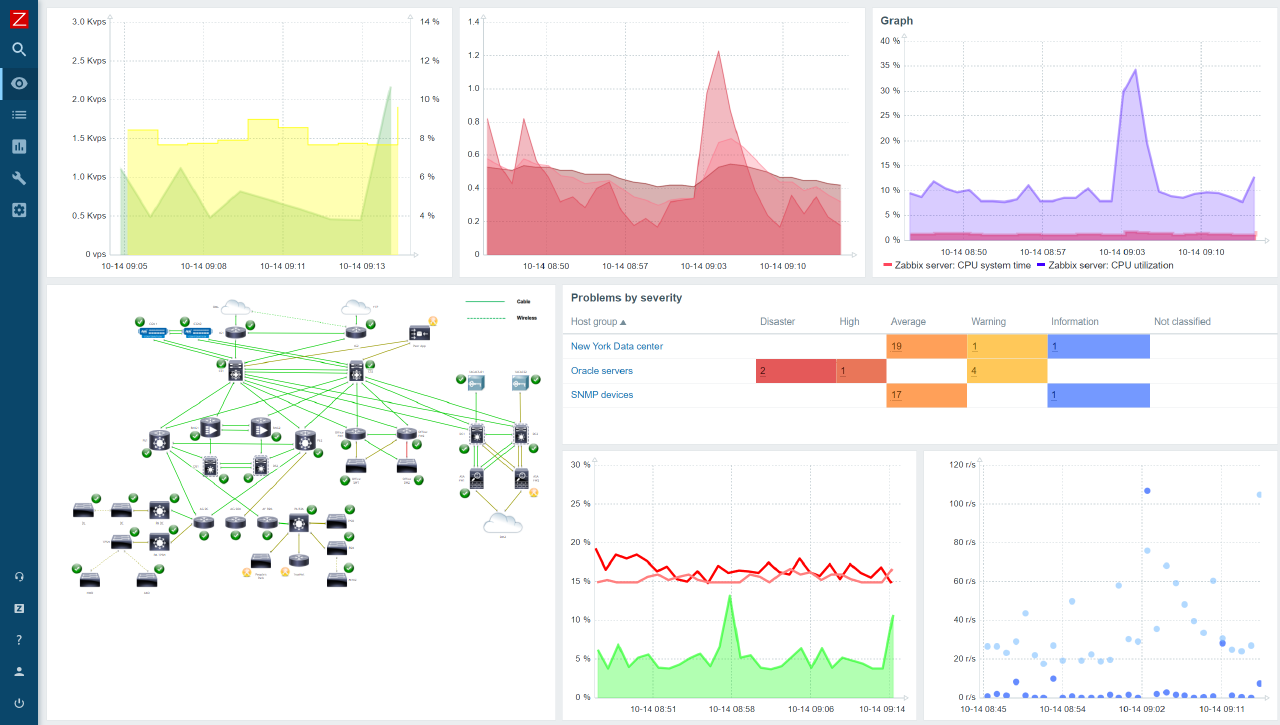
- Push-режим с агентами.
- Узлы сети.
- Триггеры.
- Шаблоны.

Prometheus
- Prometheus является базой данных временных рядов (TSDB).
- Язык запросов PromQL.
- Pull-режим работы – Prometheus сам опрашивает exporter-ы для сбора метрик.
- В случае недоступности/зависания сервера метрики за этот промежуток времени будут утеряны (дырки на графиках).
- Плохо работает в кластере, нужно либо иметь независимые ноды, либо настраивать Thanos.
Prometheus-стек
Exporter - любая программа, которая отдает метрики; Prometheus - сердце системы, собирает метрики, TSDB; Alertmanager - система управления оповещениями; Grafana - система построения графиков по метрикам.
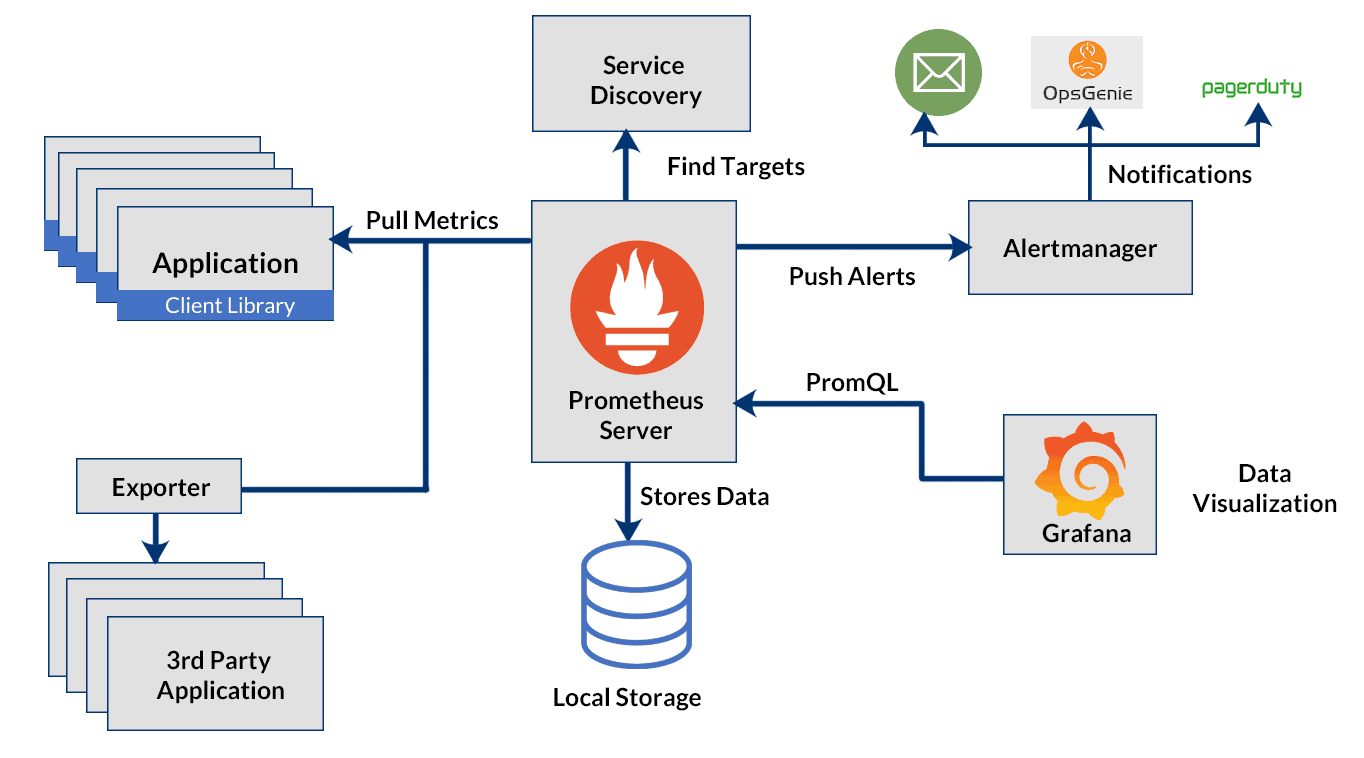
VictoriaMetrics
- Drop-in replacement (полностью совместимая замена с сохранением всех интерфейсов) для Prometheus.
- Доработанный язык запросов PromQL.
- Имеет другой подход к сжатию метрик, что позволяет до 10 раз уменьшить объем хранимых метрик за тот же промежуток времени.
- Push/Pull режимы работы.
- Кластеризация из коробки.
Средства логирования
- stderr – поток вывода "ошибок", UNIX
- syslog (sys[k]logd, 1980) – заложил основы протокола syslog
- syslog-ng (1998) – расширение фильтрами, TCP и TLS
- rsyslog (2004) – расширение RELP, buffer, модули
- Loggly (2009), Splunk, облачные и платные решения …
- Apache Flume (2009) – как часть Hadoop
- journald (2010) - как часть проекта system
- ELK/EFK (2010, JVM) – Elasticsearch, Logstash (Filebeat), Kibana
- Fluentd (2011, Ruby) – децентрализованный сбор данных
- Graylog2 (2015) – менеджер логов из разных источников
- Grafana Loki (2018) – система агрегации логов, проще
- MONQ (2019) – российская разработка основы под AIOps (искусственный интеллект для ИТ-операций) ...
ElasticSearch + Logstash + Kibana (ELK)
ElasticSearch, Logstash и Kibana изначально разрабатывались как продукты с открытым исходным кодом и развивались отдельно друг от друга, но в 2015 году они объединились под брендом Elastic и стали позиционироваться как единый продукт - ELK-стек.
Elastic изменила лицензию Elasticsearch и Kibana с полностью открытой лицензии Apache 2 на проприетарную двойную лицензию. Стеком ELK также сложно управлять в масштабе.
Иллюстрация ELK-стека
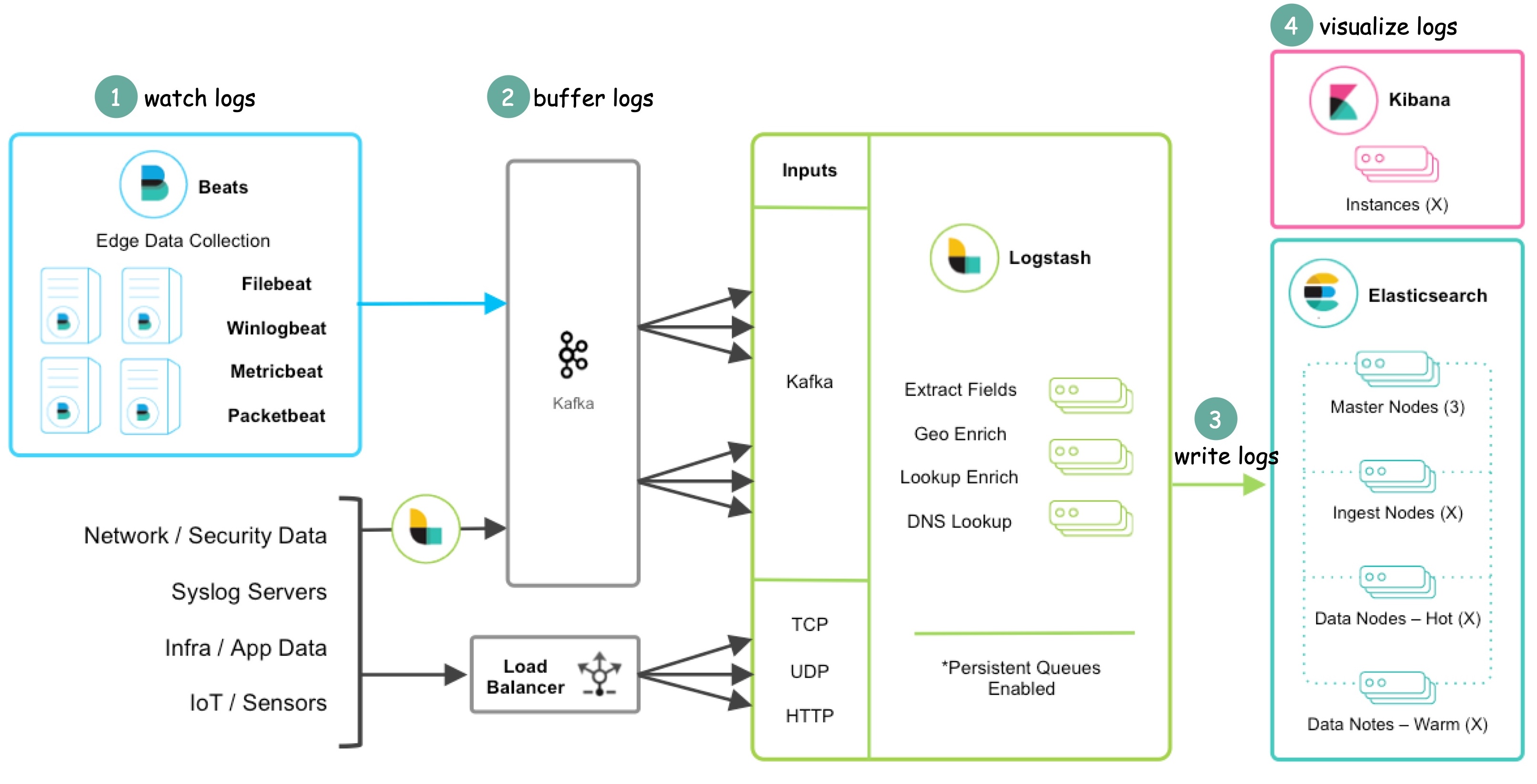
Альтернативы ELK-стеку с открытым исходным кодом
- SigNoz - это полнофункциональное приложение с открытым исходным кодом, которое обеспечивает сбор журналов и аналитику. SigNoz использует столбчатую базу данных ClickHouse для хранения журналов, которая очень эффективна при приеме и хранении данных журналов.
- Graylog - это платформа централизованного управления журналами, которая предоставляет два решения - управление журналами и управление информационными событиями безопасности. Graylog также предоставляет версию с открытым исходным кодом, называемую Graylog Open (доступ �заблокирован из РФ).
- Grafana Loki — это система для сбора, хранения и анализа логов, которая использует методы индексации на основе меток и предоставляет возможности запросов и визуализации логов облачных серверов через веб-интерфейс Grafana.
Grafana Loki
- В отличие от других подобных систем Loki основан на идее индексировать только метаданные логов — labels (так же, как и в Prometheus), a сами логи сжимать рядом в отдельные блоки.
- Таким образом получаем небольшой индекс и можем искать данные, фильтруя их по времени и по проиндексированным полям, затем сканируя оставшееся регулярными выражениями или поиском подстроки.
- Требует меньше памяти, проще в обращении.
- Сложные запросы могут работать дольше.
- Писать сложные запросы – сложнее.
- Еще немного сыроват, но активно развивается.
- Легко интегрируется с другими решениями.
Часть 2. Знакомство с PromQL
Основано на статье Знакомство с PromQL + Cheatsheet | Habr
Как работают time-series databases
Временные ряды — это потоки значений, связанных с меткой времени.
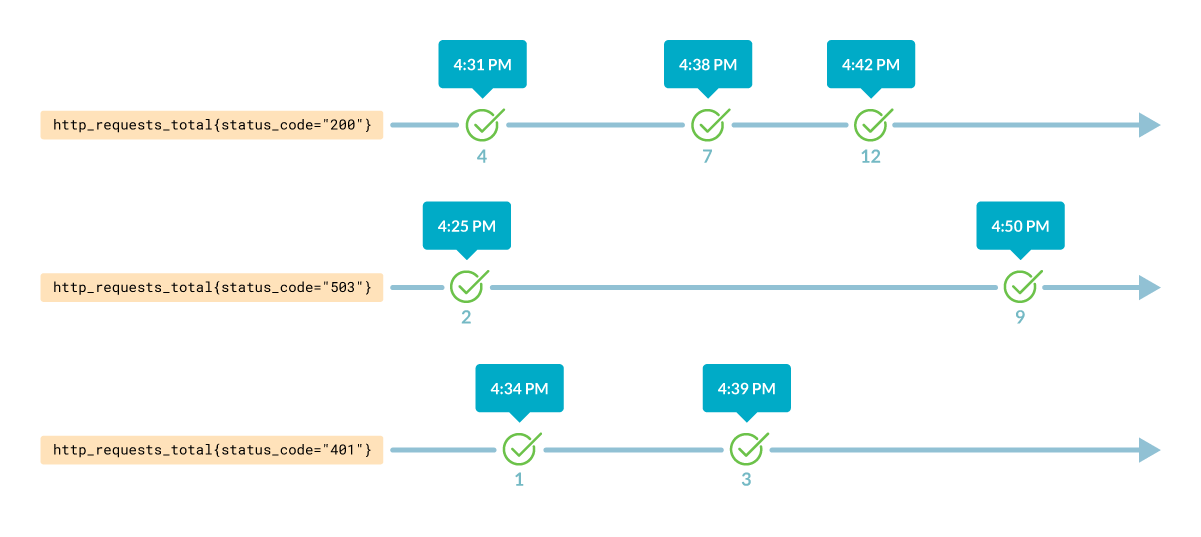
Каждый временной ряд можно идентифицировать по названию метрики и меткам, например:
mongodb_up{}
В Prometheus есть четыре типа метрик:
- Gauges (Измеритель) — значения, которые могут меняться. Например, метрика
mongodb_upпозволяет узнать, есть ли уexporterсоединение с экземпляром MongoDB. - Counters (Счетчик) показывают суммарные значения и обычно имеют суффикс
_total. Например,http_requests_total. - Histogram (Гистограмма) — это комбинация различных счетчиков, используется для отслеживания размерных показателей и их продолжительности, таких как длительность запросов.
- Summary (Сводка) работает как гистограмма, но также рассчитывает квантили.
Знакомство с выборкой данных PromQL
Выбрать данные в PromQL так же просто, как указать метрику, из которой вы хотите получить данные. В этом примере мы будем использовать метрику http_requests_total.
Допустим, мы хотим узнать количество запросов по пути /api на хосте 10.2.0.4. Для этого мы будем использовать метки host и path из этой метрики:
http_requests_total{host="10.2.0.4", path="/api"}
Запрос вернет следующие значения:
| name | host | path | status_code | value |
|---|---|---|---|---|
http_requests_total | 10.2.0.4 | /api | 200 | 98 |
http_requests_total | 10.2.0.4 | /api | 503 | 20 |
http_requests_total | 10.2.0.4 | /api | 401 | 1 |
Каждая строка в этой таблице представляет собой поток с последним доступным значением. Поскольку http_requests_total содержит определенное количество запросов, сделанных с момента последнего перезапуска счетчика, мы видим 98 успешных запросов.
Это называется instant vector, самое раннее значение для каждого потока на указанный в запросе момент времени. Поскольку семплы берутся в случайное время, Prometheus округляет результаты. Если длительность не указана, то возвращается последнее доступное значение.
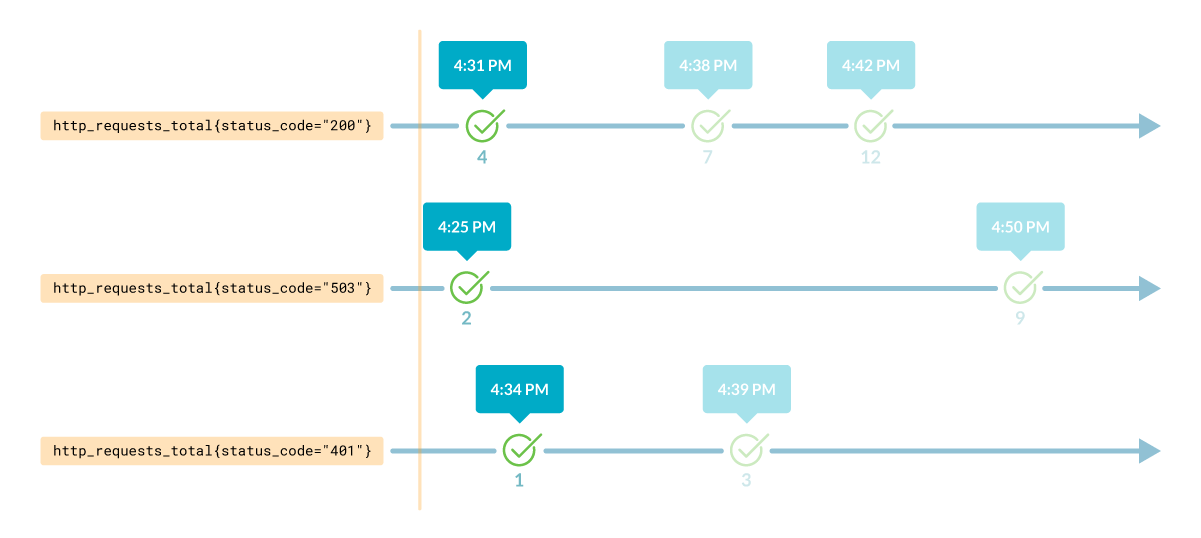
Чтобы получить значение метрики в пределах указанного отрезка времени, необходимо указать его в скобках:
http_requests_total{host="10.2.0.4", path="/api"}[10m]
| name | host | path | status_code | value |
|---|---|---|---|---|
http_requests_total | 10.2.0.4 | /api | 200 | 641309@1614690905.515 641314@1614690965.515 641319@1614691025.502 |
http_requests_total | 10.2.0.5 | /api | 200 | 641319@1614690936.628 641324@1614690996.628 641329@1614691056.628 |
http_requests_total | 10.2.0.2 | /api | 401 | 368736@1614690901.371 368737@1614690961.372 368738@1614691021.372 |
Запрос возвращает несколько значений для каждого временного ряда потому, что мы запросили данные за определенный период времени, а каждое значение связано с отметкой времени.
Это называется range vector — все значения для каждой серии в пределах указанного временного интервала.
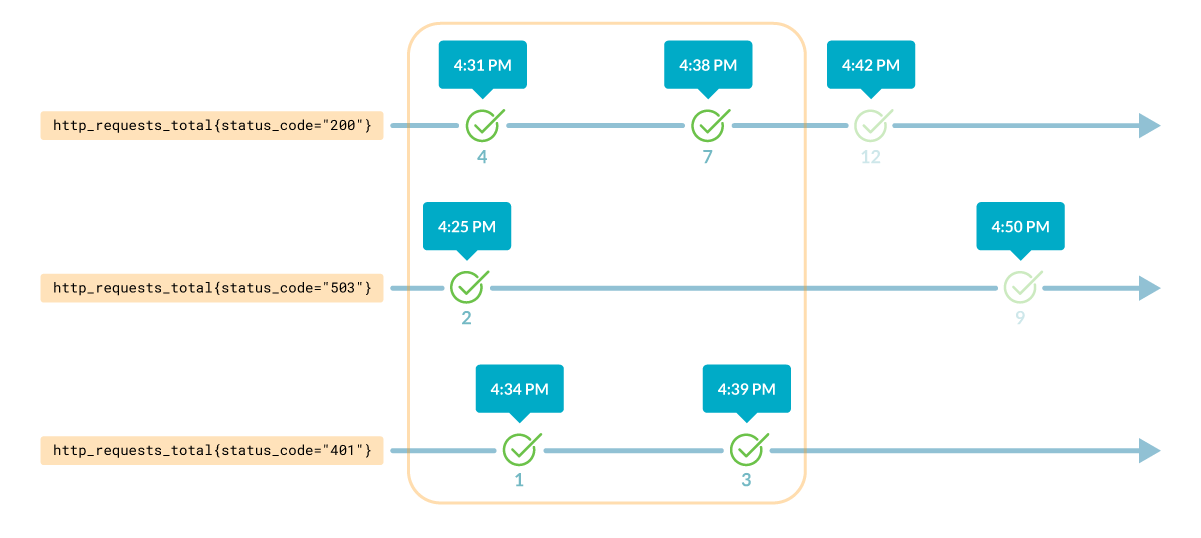
Знакомство с функциями PromQL
PromQL поддерживает большое количество функций, которые мы можем использовать для получения более сложных результатов.
При работе со счетчиками Prometheus удобно использовать функцию rate. Она вычисляет среднюю скорость увеличения временного ряда в векторе диапазона в секунду, сбросы счетчика автоматически корректируются. Кроме того, вычисление экстраполируется к концам временного диапазона.
http_requests_total[10m]
| name | host | path | status_code | value |
|---|---|---|---|---|
10.2.0.4 | /api | 200 | 100@1614690905.515 300@1614690965.515 50@1614691025.502 |
В приведенном выше примере после сброса счетчика мы получаем отрицательные значения от 300 до 50, поэтому нам недостаточно только этой метрики. Мы можем решить проблему с помощью функции rate. Поскольку он считает сбросы счетчика, результаты фиксируются, как если бы они были такими:
| name | host | path | status_code | value |
|---|---|---|---|---|
10.2.0.4 | /api | 200 | 100@1614690905.515 300@1614690965.515 350@1614691025.502 |
rate(http_requests_total[10m])
| name | host | path | status_code | value |
|---|---|---|---|---|
10.2.0.4 | /api | 200 | 0.83 |
Независимо от сбросов за последние 10 минут в среднем было 0,83 запроса в секунду.
Часть 3. Знакомство с Grafama
Панель Grafana — это базовый стандартный блок в Grafana. Каждая панель отображает набор данных из запроса источника данных с помощью визуализации.
Панели Grafana поддерживают различные визуализации, которые являются визуальными представлениями базовых данных.
Панель мониторинга Grafana — это коллекция панелей, расположенных в строках и столбцах. Панели обычно отображают связанные наборы данных. В Grafana можно создать несколько панелей мониторинга. Дополнительные сведения о панелях мониторинга см. по следующим ссылкам:
Часть 4. Знакомство с демо-системой
Вы можете самостоятельно поднять с помощью Docker Compose демонстрационный пример. Для этого, скачайте проект и выполните docker compose build && docker compose up -d.
В качестве альтернативной демо-системы вы можете воспользоваться системой из этого репозитория.
В этом примере вы можете запустить простое приложение Flask, имеющее разные конечные точки. Перечислим данные конечные точки:
<address_app>/- возвращает всегдаOK.<address_app>/view/<id>- возвращаетView <id>. В качестве<id>ожидается UUID.<address_app>/buy/<id>- возвращаетBuy <id>. В качестве<id>ожидается UUID.<address_app>/rolldice- возвращает случайно число от1до6. Иногда возвращает ошибку500, если число было сгенерировано некорректное.<address_app>/metrics- метрика, собираемая Prometheus.<address_app>/one,<address_app>/two,<address_app>/three,<address_app>/four- четыре метода, с различной задержкой возвращающиеok.<address_app>/error- метод, который всегда возвращает:(с кодом ошибки500.
Часть 5. Выполнение произвольных запросов в Grafana
Материал основан на Example dashboard | rycus86 /prometheus_flask_exporter.
Перед тем, как перейти в Grafana, рекомендуется вызывать методы приложения, которые представлены выше. Тогда вам удастся собрать некоторую метрику.
Перейдите в Grafana по адресу <address_grafana>:
Далее перейдите на вкладку Explore:
Выберите источник данных Prometheus:
Выполните предложенные запросы ниже.
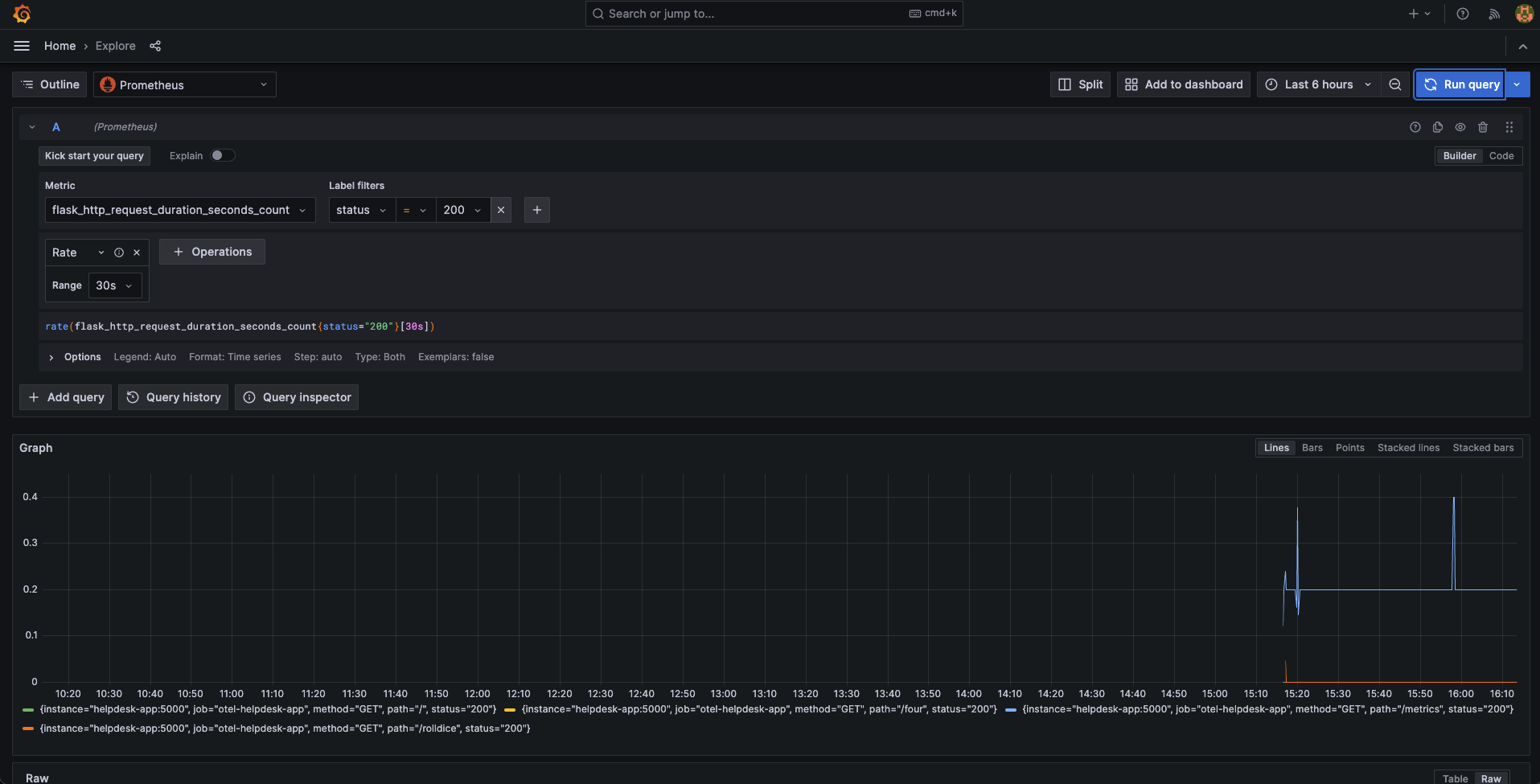
Количество запросов в секунду
Количество успешных запросов Flask в секунду. Показано для каждого пути.
rate(
flask_http_request_duration_seconds_count{status="200"}[30s]
)
Количество ошибок в секунду
Количество неудачных ответов (не HTTP 200) в секунду.
sum(
rate(
flask_http_request_duration_seconds_count{status!="200"}[30s]
)
)
Общее количество запросов в минуту
Общее количество запросов, измеренных с интервалом в одну минуту. Отображается для каждого кода состояния HTTP-ответа.
increase(
flask_http_request_total[1m]
)
Среднее время отклика [30 секунд]
Среднее время отклика, измеренное с интервалом в 30 секунд для успешных запросов. Показано для каждого пути.
rate(
flask_http_request_duration_seconds_sum{status="200"}[30s]
)
Длительность запроса [с] - p50
50-й процентиль длительности запросов за последние 30 секунд. Другими словами, половина запросов завершается за это время (min / max / avg). Показано для каждого пути.
histogram_quantile(
0.5,
rate(
flask_http_request_duration_seconds_bucket{status="200"}[30s]
)
)
Длительность запроса [с] - p90
90-й процентиль длительности запросов за последние 30 секунд. Другими словами, 90 процентов запросов завершаются за (минимальное / максимальное / среднее) время. Показано для каждого пути.
histogram_quantile(
0.9,
rate(
flask_http_request_duration_seconds_bucket{status="200"}[30s]
)
)
Для дальнейшего изучения
- How to build a PromQL (Prometheus Query Language) | Is it Observable
- Intro to Prometheus for Developers | DEV
- Наблюдаемость .NET с помощью OpenTelemetry - .NET
- Основные аспекты наблюдаемости систем
- Observability: как наблюдать за системой?
- Практическое руководство по реализации Observability в DevOps
- Как поп�робовать ELK-стек за один вечер и наконец-то перестать grep'ать логи
- Система мониторинга Zabbix для начинающих
- Распределенное логирование или как дебажить, когда микросервисы
- Microservices Monitoring: Challenges, Metrics, and Tips for S0uccess
- Мониторинг микросервисных приложений: взгляд SRE
- Просто о сложном: трассировки в микросервисах
- What Is OpenTelemetry? Concepts, Architecture, and a Tutorial
- Getting Started with OpenTelemetry Python
- OpenTelemetry Collector: A Friendly Guide for Devs
- OpenTelemetry на практике
- OpenTelemetry
- Павел Труханов. Мониторинг Postgres по USE и RED. Расшифровка с PGConf.Russia
- Prometheus vs. VictoriaMetrics (VM)
- Jaeger для трассировки в микросервисной архитектуре
- Zabbix vs Nagios vs Pandora FMS: подробное сравнение
- Знакомство с PromQL + Cheatsheet | Habr
- Мониторинг микросервисов Flask с помощью Prometheus | Habr
- Основы мониторинга (обзор Prometheus и Grafana) | Habr
- PromQL Cheat Sheet | PromLabs